Stavo pensando una cosa, in un film o filmato di solito esistono moltissimi fotogrammi in cui una stessa immagine si ripete per svariate decine o addirittura centinaia di fotogrammi senza modificarsi oppure modificandosi di pochissimo nel colore di alcuni pixel. E se trovassi un modo per codificare quei fotogrammi ripetitivi in pochi byte che si limitino a specificare al programma di riproduzione che da quel momento in poi ci saranno tot fotogrammi tutti uguali?
E se a questo metodo affiancassi un altro algoritmo che si dedichi a codificare solo quei pixel che cambiano oltre una certa soglia il loro colore, lasciando così invariato il resto dell'immagine già codificata e quindi riprodotta in precedenza? Forse riuscirei a ridurre anche considerevolmente le dimensioni del file senza imbarcarmi in complicatissime formule matematiche con le quali, per ora, non ho alcuna confidenza.
Vi faccio uno schemino esplicativo di quello che intendo.
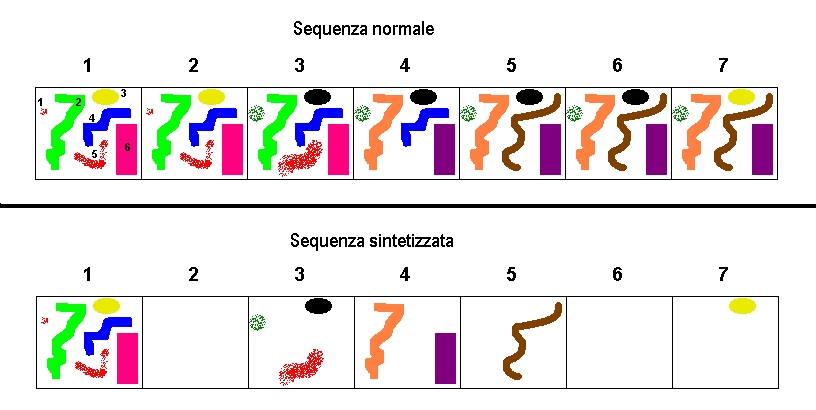
Come si può vedere nell'immagine, in un filmato avm classico ogni fotogramma, anche se identico al precedente, viene codificato comunque in tutte le sue parti. Nella sequenza sintetizzata invece vengono codificate solo quelle aree, e i pixel in quelle aree, che si sono modificati durante la registrazione/riproduzione, riducendo così notevolmente lo spazio occupato dal filmato.
Nel presente caso, ad esempio, in un file normale (non compresso) troveremo scritto (ovviamente in bytes):
Fotogramma 1: elemento 1, 2, 3, 4, 5, 6
Fotogramma 2: elemento 1, 2, 3, 4, 5, 6
Fotogramma 3: elemento 1, 2, 3, 4, 5, 6
Fotogramma 4: elemento 1, 2, 3, 4, 5, 6
Fotogramma 5: elemento 1, 2, 3, 4, 5, 6
Fotogramma 6: elemento 1, 2, 3, 4, 5, 6
Fotogramma 7: elemento 1, 2, 3, 4, 5, 6
In un file compresso, quindi a sequenza sintetizzata, troveremo invece scritto soltanto:
Fotogramma 1: elemento 1, 2, 3, 4, 5, 6.
Fotogramma 3: elemento 1, 3, 5.
Fotogramma 4: elemento 2, 6
Fotogramma 5: elemento 4
Fotogramma 7: elemento 3
Il che è molto meno ingombrante della prima versione e non si perde nulla in termini di fedeltà all'originale.
Certo, quella rappresentata nell'esempio è una situazione abbastanza fortunata, nel senso che in realtà è abbastanza più complessa la computazione in fase di masterizzazione, l'importante però è che durante la fase di riproduzione la velocità di decodifica dei fotogrammi sia la più elevata possibile, cosa che sicuramente questo metodo garantisce.
Edited by yareol - 17/5/2011, 14:15
 XmX
XmX 








 :
:
 mi hai fatto tornare la voglia di programmare, ho sempre trovato bello il basic, ma questo li supera tutti.
mi hai fatto tornare la voglia di programmare, ho sempre trovato bello il basic, ma questo li supera tutti. Ti sei fatto una vacanzina in giro per il mondo?
Ti sei fatto una vacanzina in giro per il mondo?